
AI 重塑千行万业,其训练和推理都高度依赖强大的算力支持。随着应用场景的不断拓展和技术的不断深挖,AI 对于算力的需求呈指数级增长。如何满足算力需求的激增已经成为当今亟待解决的一大挑战。
硬件层面,当前半导体制程工艺接近物理极限,进一步提升面临极大困难,业界正围绕新型计算架构(比如存内计算、光子计算等)开展研究;软件层面,通过改进算法设计或开发新的算法可有效提升现有硬件计算平台效率,有望突破当前硬件算力极限。
“面对 AI 算力提升面临的挑战,我们从软件和算法的创新来进行突破,聚焦稀疏化算法,通过软硬协同设计,可能将现有 AI 算力提高 1-2 个数量级。”墨芯人工智能科技(深圳)有限公司(下文简称“墨芯”)联合创始人兼首席科学家严恩勖博士告诉「问芯」。

图|墨芯联合创始人兼首席科学家严恩勖博士(来源:受访者)
严恩勖博士毕业于卡内基梅隆大学。“我从本科、硕士到博士阶段的研究方向都是围绕 AI 训练推理优化方面。在 AI 领域,早先 GPU 并没有现在这么热门,直到 2014 年 GPU 才成为主流的 AI 计算平台。在此之前,大部分的训练算法和推理算法是在 CPU 上实现的。”他介绍说。
从问界到享界,华为入局汽车市场更加深入。如今,华为与车企合作更加紧密,不仅强化智选车模式合作,更在智能技术研发领域“牵手”,展现其在造车领域的野心与计划,“造车”全面提速。

“我们当时的研究主要针对软件优化,由于在 AI 计算方面 CPU 的算力比 GPU 的算力弱得多,因此需要靠软件来为 CPU 减少计算量,即通过减少算法的计算复杂度从而让训练推理更快。”他解释说。
“在我读博期间,深度学习爆发,GPU 也跟着开始热门起来。这基本上可以算是一个范式的转移,AI 计算更倾向于使用硬件来加速。”他说道,“一方面,算力更充足,进而可以计算更复杂的模型,开展更大规模的训练。但是,另一方面,主导整个 GPU 市场的英伟达打造的是闭源生态,不论是硬件架构还是软件系统都很难基于此进行自主创新。”
在严恩勖看来,“未来的 AI 训练推理需要‘软硬结合’。单纯基于软件算法的创新是行不通的,没有硬件支撑无法实现更大算力,而单纯基于现有的硬件却比较受限,难以实现创新。数据格式的创新必须要协同硬件一起去进行设计。”
2018 年,他遇到卡内基梅隆大学校友王维(墨芯人工智能创始人兼 CEO,硕士毕业于卡内基梅隆大学 ECE 专业,拥有 15 年硅谷数模混合电路和 CPU 高速链路架构经验,曾在美国高通和英特尔担任架构师,是英特尔 5-10 代 CPU 处理器的核心成员。),基于对稀疏化算法的认同,他们在美国硅谷创立了墨芯,而后将公司落地中国深圳,专注于通过稀疏算法和软硬协同开发具有更高算力、更低功耗的通用 AI 计算平台,提供云端和终端 AI 芯片加速方案。
基于稀疏化算法和软硬协同设计打造 AI 计算平台
据介绍,整个墨芯团队中约 90% 都是研发人员,包括硬件系统、软件系统,其中软件又分成系统方向和 AI 大模型方向。“我主要负责与 AI 有关的算法和软件,比如模型的算子,或是数据的格式。我们聚焦的是一种特殊的新型数据格式,即‘稀疏化算法’。”严恩勖说道。
所谓稀疏化算法,是一种通过优化 AI 计算过程中的大量矩阵运算,剔除无效元素,以及减少冗余和重复内容的计算方法,在许多实际应用中,稀疏化算法能够显著提高计算效率和性能,同时降低能耗和成本,是全球公认的新一代 AI 计算技术。
“对于海量数据,普通的 GPU 或者是稠密运算格式都是统一处理,即全部使用相同的方式去处理数据,而稀疏化算法的核心在于可以在数据中采用不同的方式去处理。”他解释说,“如此一来,就可以在非常细粒度的层面上实现异构,进而可以在成本与算力之间取得更好的平衡点。在我们的实际案例中,采用稀疏化算法的算力可以提高一个数量级。”他指出。
据介绍,墨芯开发的“双稀疏化算法”拥有全球专利,对比使用一种稀疏化,其通过神经网络的“权重稀疏化+激活稀疏化”进一步提高效率,革新了当前的 AI 计算模式和芯片架构,有望从根本上突破 AI 算力瓶颈。与此同时,墨芯的创新不单停留在算法层面,还通过软硬协同架构设计,打造了新一代的 AI 计算平台。
“我们推出的产品围绕算法和软硬协同解决算力瓶颈,去满足业界对于高算力的需求,对标的是国际头部厂商的旗舰产品。”他说道,“我们并不是在半导体制程工艺方面达到超高算力的一些指标,而是通过数据格式创新、算子创新,在相同物理算力下实现高于友商旗舰产品在同样制程的水平,这也是我们的愿景。”

图|墨芯 Antoum 芯片(来源:公司官网)
据介绍,墨芯推出的首款双稀疏化芯片 Antoum® 支持高达 32 倍稀疏率,主要面向云端人工智能推理场景,广泛支持 Transformer、CNN、RNN、LSTM 等模型以及多种数据类型,目前已经实现量产;基于 Antoum® 芯片,墨芯推出了 S4、S10、S30 和 S40 系列 AI 计算卡,能够提供超高算力、超低功耗和超高能效比的 AI 计算加速。
“在全球权威 AI 测评 MLPerf 中,墨芯 AI 加速卡连续两届获得冠军,算力高于业内国际头部厂商的旗舰产品。这基本上从技术上证明了通过新的算法硬件协同,制程相对落后也可以实现更强性能。”他表示。
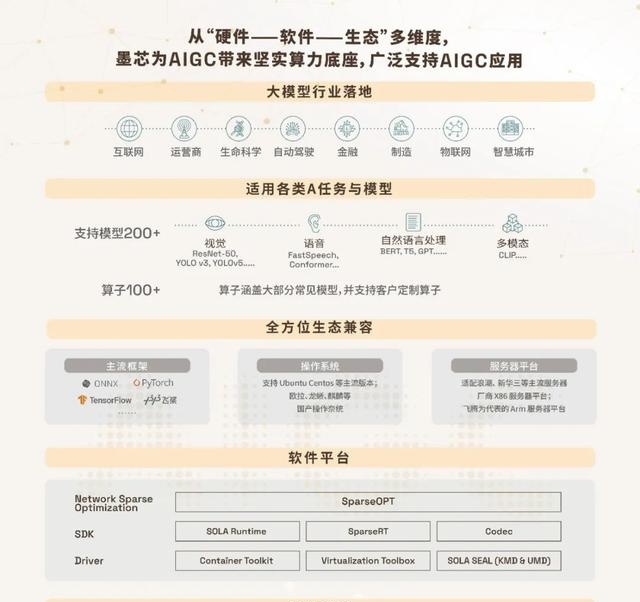
图|墨芯 AI 计算卡系列产品(来源:公司官网)
“墨芯的一代产品在部分落地场景上只需要较少的迁移成本,因此面向的主要是在模型和任务选择方面更加固定的客户群体,可以投入一定的成本来做迁移,一来实现国产化,二来提高性价比。”他介绍说。
应用场景方面,“不管是 CNN 还是 RNN,一代产品的训练成本低、迁移成本低,目前已有很多行业客户进行了大量部署。”严恩勖说道。
现阶段处于‘百模大战’,长期更看好推理
从稀疏化算法、大模型推理引擎,到 AI 芯片,再到整体解决方案,以及构建稀疏计算生态,在严恩勖看来,这套体系是 Top-Down,是自上而下且自外而内的。“要从外部条件,包括技术的趋势、市场的趋势以及整个供应链的趋势,去倒推我们内部怎么去设计才能够在这三者之间达到一个最佳平衡。”严恩勖解释说。
举例来说,首先关注 AI 本身需要什么,不管是 Transformer 模型的一些特性,还是一些推理算法的设计,都有客观定律。“一方面,我们积极跟进当前最新的一些算法趋势,另一方面,我们站在‘巨人肩膀’上探索稀疏数据格式怎么样可以进一步提升。”他表示。
“所以,需求的来源就是:第一,技术的趋势本身是什么;第二,我们在上面又额外添加了什么。这两点就基本上决定了我们算法的需求。”他指出,“这个需求会给到软件、硬件。软件和硬件就要从另外两个维度进行设计,一个维度是硬件的可实现性,比如面积、功耗,以及架构等,能够将需求实现到什么地步,其代价是什么,需要取得一个平衡。”他表示。
“在硬件和算法之间取得一定的平衡之后,就证明它已是一个可执行的设计,接下来加入第三个维度,使其符合开发者本来的习惯。”他指出。比如,开发者们习惯使用的算子定义是到哪一种粒度。“在这些方面,我们要以一种用户本来习惯的方式并且能‘随装随用’去开发一款优秀的产品。”他解释说。
“接下来,就是实现与验证,这也是大部分研发人员所做的工作。最终再由算法、软件的逐步逐级的往上验收,看最终是不是达到理想的效果。”他表示,“当然,这个过程中还会牵涉到很多不同层级的仿真,比如有数据格式算法层的仿真,硬件系统级的仿真等,根据不同级别分别去验收,涵盖不同的精度、性能方面。”他补充说。
对于国内 AI 算力芯片市场,严恩勖表示,“现阶段处于一个过渡期,我们更看好推理,长期来看推理才是 AI 的市场,但短期内仍然处于‘百模大战’的阶段,这个时期有大量训练需求。推理方面,今年只能说是开始起步,我们也比较期待推理爆发的时间点。”他说道。
纵观全球 AI 算力产业,“大模型时代的竞争,归根到底就是要把模型的延时、并发、吞吐等各个方面的指标做好,同时还要兼顾成本能效比。墨芯从 AI 的算子的需求角度,来倒推我们的东西应该如何设计。所以,我认为墨芯的核心竞争力在于是直接针对 AI 的需求去开发的。”严恩勖说道。
在他看来股票配资找哪家好,把一件事情做到满分比把很多事情都只做到 80 分更为重要。“对比国际巨头,我们接下来还有很多需要完善和拓展的地方,比如传统 IC 设计、软件设计方面,我们还不具备巨头的成熟体系,这都是我们未来持续发力的方向。”严恩勖表示。
Powered by 专业线上配资平台_专业股票配资平台_专业低息配资平台 @2013-2022 RSS地图 HTML地图